1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
# we stick with nginx var names here and prefix the exported metric with nginx_ by using "as"
# "by" allows us to specify our labelling/grouping
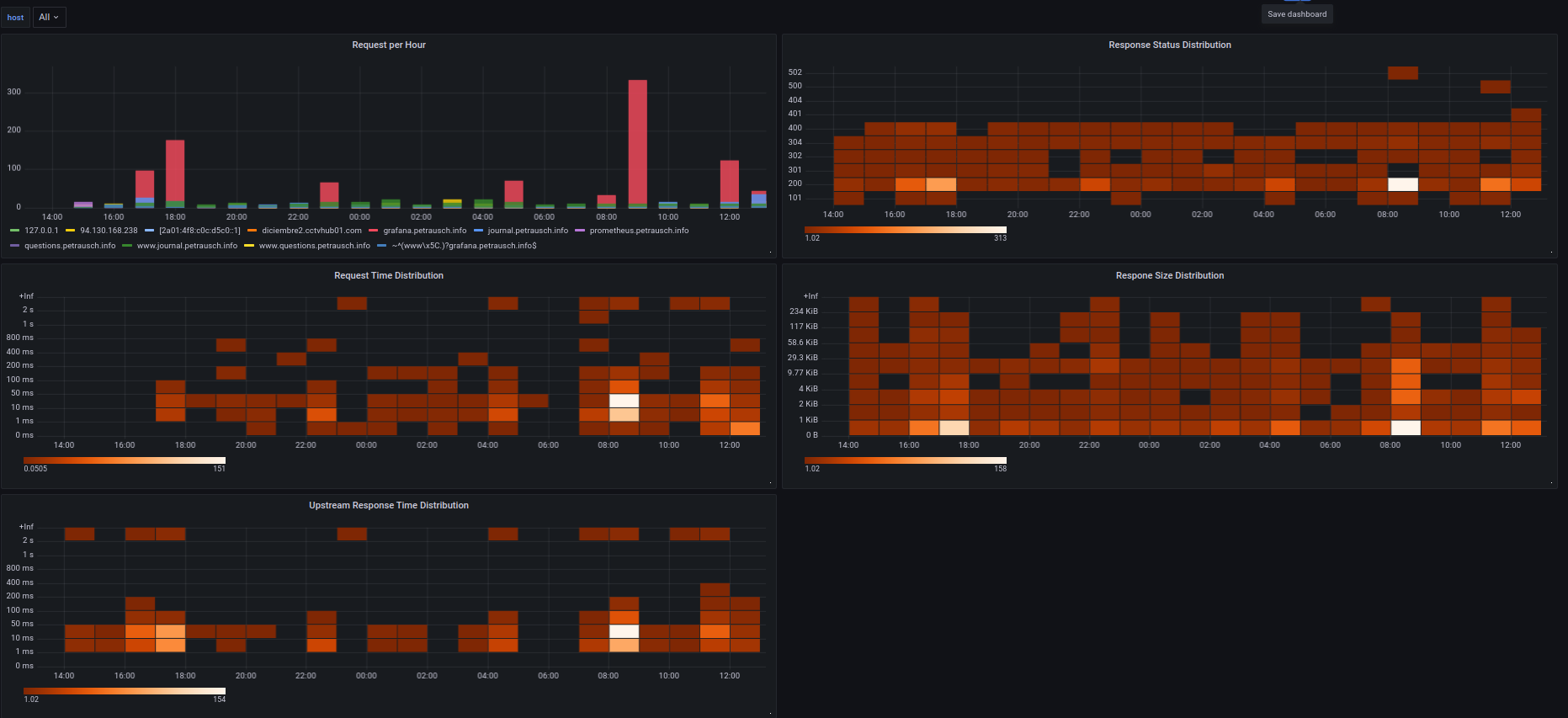
counter request_count by nginx_host, nginx_method, nginx_status as "nginx_request_count"
histogram request_length_bytes by nginx_host, nginx_method, nginx_status buckets 1024, 2048, 4096, 10000, 30000, 60000, 120000, 240000 as "nginx_request_length_bytes"
histogram bytes_sent by nginx_host, nginx_method, nginx_status buckets 1024, 2048, 4096, 10000, 30000, 60000, 120000, 240000 as "nginx_bytes_sent"
counter body_bytes_sent by nginx_host, nginx_method, nginx_status as "nginx_body_bytes_sent"
histogram request_time_hist by nginx_host, nginx_method, nginx_status buckets 1, 10, 50, 100, 200, 400, 800, 1000, 2000 as "nginx_request_time_milliseconds"
histogram upstream_connect_time by nginx_host, nginx_method, nginx_status buckets 1, 10, 50, 100, 200, 400, 800, 1000, 2000 as "nginx_upstream_connect_time_milliseconds"
histogram upstream_header_time by nginx_host, nginx_method, nginx_status buckets 1, 10, 50, 100, 200, 400, 800, 1000, 2000 as "nginx_upstream_header_time_milliseconds"
histogram upstream_response_time by nginx_host, nginx_method, nginx_status buckets 1, 10, 50, 100, 200, 400, 800, 1000, 2000 as "nginx_upstream_response_time_milliseconds"
counter nginx_log_nomatch_count
# the following pattern matches exactly the tab-separated fields in our custom access_log format
# if you want to customize...this pattern should be updated to match changes you make in the nginx log format.
/^/ +
/(?P<msec>\d+)\.\d+\t/ + # settime() needs just the seconds so we exclude the .milliseconds part
/(?P<host>\S+)\t/ +
/(?P<server_port>\S+)\t/ +
/(?P<request_method>\S+)\t/ +
/(?P<uri>\S+)\t/ +
/(?P<content_type>\S+)\t/ +
/(?P<status>\S+)\t/ +
/(?P<request_length>\d+)\t/ +
/(?P<bytes_sent>\d+)\t/ +
/(?P<body_bytes_sent>\d+)\t/ +
/(?P<request_time>\d+\.\d+)\t/ +
/(?P<upstream_connect_time>\S+)\t/ +
/(?P<upstream_header_time>\S+)\t/ +
/(?P<upstream_response_time>\S+)/ +
/$/ {
settime($msec)
request_count[$host][$request_method][$status]++
request_length_bytes[$host][$request_method][$status] = $request_length
bytes_sent[$host][$request_method][$status] = $bytes_sent
body_bytes_sent[$host][$request_method][$status] += $body_bytes_sent
# Especially, for static files, the request time is often below a millisecond, hence 0. We set them to 1, to
# count them in the histogram
$request_time*1000.0 < 1 {
request_time_hist[$host][$request_method][$status] = 1.0
} else {
request_time_hist[$host][$request_method][$status] = $request_time*1000.0
}
# mtail is happier doing counters with floats/ints.
# nginx logs '-' when there isn't a value which
# we check for - and skip updating these counters if found.
# otherwise we cast the string to a float and increment the counter.
$upstream_connect_time != "-" {
upstream_connect_time[$host][$request_method][$status] = float($upstream_connect_time)*1000
}
$upstream_header_time != "-" {
upstream_header_time[$host][$request_method][$status] = float($upstream_header_time)*1000
}
$upstream_response_time != "-" {
upstream_response_time[$host][$request_method][$status] = float($upstream_response_time)*1000
}
} else {
# our pattern doesn't match.
# in this example since we have a single program with a single log file...it should always match
# or we have a bug.
# can use this metric to detect when our parser is failing.
nginx_log_nomatch_count++
}
|